WARNING: It has come to my attention that this page, that contains my personal notes for my Databases module during my First Year of Computer Science at university, was indexed by Google and is being shown to students. This page is a really good resource for Databases, but be aware that this is alot more info than you need for the exam. I apologize for the confusion.
1.Introduction
File based approach to information storage
One possible way of storing information would be to store each set of data needed on a seperate text file and then implement a program to do specific queries on the text files.
Limitations to file based approach
This may seem like a perfectly good solution however there are many limitations to it.
- No recovery - If something goes wrong you can't recover it.
- Inefficient - large data sets are very inefficient to query if held in text files.
- No simultaneous access - It makes simultaneous access very difficult as when querying a file it must be locked. Additionally hiding files or fragments of files is a difficult task with a file based system.
- Separation and isolation - Each program holds it's own set of data to deal with one task and may not be aware of useful data held by another program
- Duplication - Different programs may hold the same data and so that data is redundant and simply wastes space/ increases chance of desynchronisation.
- Data dependence - Each file may have a different format, so the structure is hard coded into the program making it hard to transfer data between programs.
- Fixed queries - Programs are written with specific queries to meet requirements and if a new requirement is needed a new program is needed.
Database approach to information storage
Database: A collection of data related in a logical manner which is designed to provide all the necessary info for an organisation
Requirements for a DBnv
- One central repository of data shared by all users/departments
- all data has a minimum amount of duplication/redundancy
- Large databases may have a "data dictionary" which describes the DB data. (e.g schema)
Database management system
This is a system which allows users to have complete control over the DB. Giving functions to define/create/maintain the DB
A DBMS has two features:
Data Definition Language: The schema. It allows users to define how the database should be. Including the data types the structures and the constraints of the data.
Data Manipulation Language: The queries. It's the language you use to manipulate the database. A common one is SQL.
DBMS also offers:
- Security - Users can only access what they're allowed to access
- Concurrency - Multiple queries can be done on the same data
- Recovery - If something goes wrong you can undo it.
Components of the DBMS environment
- Hardware - The computers storing the data
- Software - the DBMS managing the data
- Data - the actual stuff which you are storing + the metadata e.g schema
- Procedures - The documented instructions on how to use the DB
- People - The people who run the queries and mange the DB
Disadvantages to using DB over file system
Whilst there are lots of very clear advantages, to be balanced lets go through the disadvantages too
Compared to a file system a DB is/has:
- More complex
- Higher cost to implement
- Additional hardware cost
- Slower processing for SOME applications
- Higher impact if things go wrong.
A noSQL DB solves these problems by using a hybrid of a file system and a DB.
2. Database schemas and planning
Transactions and concurrency control
We want for the DBMS to be able to be trusted and for all operations to be completed. It should be reliable and always be in a consistent state.
It needs
- Database recovery
- Concurrency control protocols
- This where database access are prevented from interfering with others.
Transaction: An action carried out which reads/updates database.
Database recovery
- During execution of a transaction the data may be in an inconsistent state, where constraints may be violated
- Committed: transaction commited successfully
- Rolled back: When it was not completed successfully.
Concurrency control
- process of managing simultaneous operations on the DB, preventing them interfering with each other.
- This allows multiple users to edit the DB at the same time and all to execute correctly.
Abstract data models
DDL: specifies entities/attributes/relationships/constraints. However it is too low level to understand for most people.
Data model: Intuitive concepts describing data
Types of data organisation
The three way of charecterizing the data is:
- Structured data
- Semi-structured data(XML)
- Unstructured data
Structured data
- Data represented in a strict format such as a relational data model (tables, tuple, attributes)
- The DMBS ensures that everything has the right structure and maintains integrity.
Semi-structured data
- Schema mixed in with data, so you don't know in advance how it's structured.
Unstructured data
- No structure to document
- E.g text document or webpage html
Relational data model
- Relationships are tables (columns + rows)
- The attributes are the colums
- And the tuples are the rows.
Entity-Relationship (ER) model
This is a graphical description of the DB
- It specifies the data objects and the important properties
- Also the associations between the entities ( relationships)
- Includes constraints
Notations for the ER model:
- Crow's foot notation
- UML notation
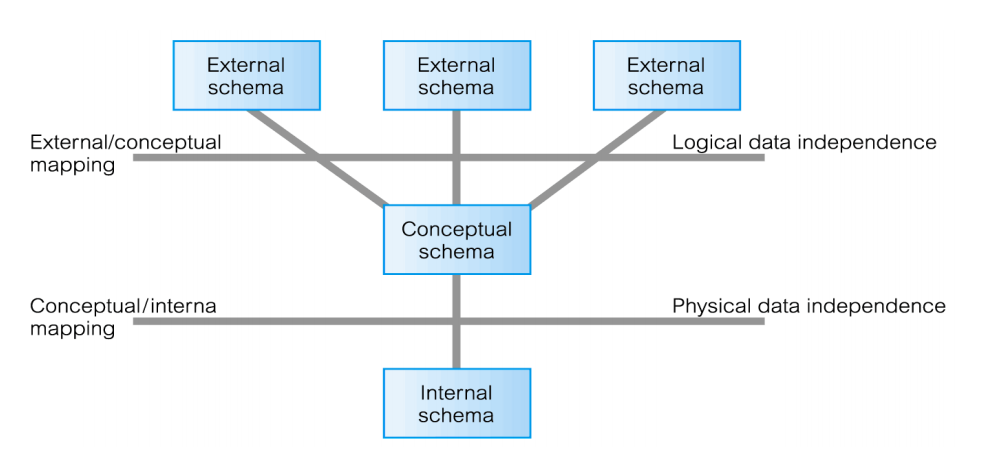
3-level ANSI-SPARC* Architecture
- External level: Data that users care about
- Conceptual level: The logical structure of the data that the DBA cares about
- Internal level: How the data is physically stored in the DB. (Data Structures, algorithms)
Derived attributes vs attributes
- Derived means it is based on an attribute with a formula applied
- Attributes are actual values stored in the DB
DB schema
- DB schema: this describes everything in the DB
- DB instance: Describes the data at a particular moment
The aim of the schema is to allow users to all have access to the same DB instance with customized views depending on what part they need to see themselves.
Data independence
Upper levels in the DB schema should not be affected by changes in the lower level
Logical data independence: External schemas called views don't change if change the logical structure of the data.
Physical data independence: Conceptual schema doesn't change if we change the internal schema.
Three main phases of Database Design
- Conceptual design: Make a high level model of the data
- This identifies the users requirements
- Is independent of physical needs
- Gives a fundamental understanding of the system
- logical design: Make a relational data model of the data
- Use the conceptual design to map out the entities/relationships
- Normalise data
- Physical design: Describe the database implementation. Specify storage structures for an optimum performance
3. Relational model
A relational model represents a DB as a collection of relations and constraints.
This is basically the same as the entity relationship model which we'll talk about next so I'll just gloss through this section and use it as an overview.
Terminology
- Relation - table with rows and columns which logically stores entity occurrences and their tuples
- Attribute - A named column of a relation with a unique name. It stores properties of entities
- Domain of attribute - Allowed values
- Tuple - Row of relation
- stores attributes for a given entity occurrence
- Cell - Intersection of row and column
- a specific attribute value for a specific entity occurrence
- Degree - Number of attributes a given relation has.
- num of properties an entity has
- Cardinality - Number of tuples in a relation
- Number of entity occurrences an entity has
- Normalised - means the relation is appropriately structured to reduce redundancy and fit certain rules. These are the normal forms.
Properties
- Relation name is distinct
- Attributes have distinct names
- Values of attributes are from same domain
- Each cell has one atomic value
- Each tuple is distinct so no duplicate tuples
- Ordering of attributes and tuples doesn't matter.
4. The entity relationship model
This is a graphical description of the DB to allow people perhaps without such advanced knowledge to understand the db. Aka engineers.
- Set of requirements
- Types of things you want to represent data
- Attribute of things
Main components
Entity
- Thing that is of enough concern to be represented separately.
- Represented by rectangles
- Entity occurrence: One unique identifiable occurence of an entity
Relationship
- Named association between two entity types. Which has some context in the database
- Represented by labelled line
- Cardinality: how many entity occurrences of an associated entity type is a single entity occurrence related to?
- One-to-one
- one-to-many
- many-to-many
- Use crows foot notation to notate the cardinality. (labelled line splits off depending on cardinality)
- Optionality and participation
- If it participates optionally it has partial participation else it has total participation
- Total participation represented by vertical bar
- Partial participation represented by circle

Attribute
This is the set of all common characteristics that are shared by entity occurrences of a particular type.
- Primary keys are underlined
- Attributes represented by labelled ellipses attached to rectangles
- OR all attributes in lower part of entity rectangle.
- Single attribute has one component, composite attribute has multiple components. E.g address is composite.
- Derived attribute, derived using function using differently stored data. E.g age comes from DOB
5: Dependencies and Normalisation
Normalisation
This is a bottom up strategy, basically we start with all the data and attributes stored in the tables. Then from that we figure out optimal relationships such to have the best designed relational database
Database redundancy
it should have No redundancy: Every data item is stored in one place.
- This minimises the space required
- Simplifies the maintenance of the database
- If it was stored in two places then every time we updated it we would need to change two elements
- Dependencies between attributes cause redundancy. (Knowing one attribute should not let you know any other attribute.)
Data anomalies Terminology
Modification anomaly: Don't change all instances of a specific value, after modifying one.
Deletion anomaly: Losing other values because you delete one items data
Insertion anomaly: Where when new data items are added, we need to add information about other entities.
Decomposition
To fix the data anomaly problems, remove the dependencies and redundancy by splitting data into multiple tables. Where data which must stay consistent between values of same attribute value, is stored one time in a different table
Relational keys
- Candidate keys: Minimal (not minimum) set of attributes whose values uniquely identify the tuples
- Primary key: Candidate Key which identifies the row
- Alternate key: Keys which are not selected as primary but are candidate keys
- Simple key: Key consiting of only one attribute
- Composite key: Key consists of several attributes.
Functional data dependencies
This describes the relationships between attributes in the same relation.
Let A and B be two sets of attributes. Then B is Functionally dependent on A if each value of A is associated with exactly one value of B
- Determinant: The set of attributes on the LHS of the functional dependency
- Dependent: Set of attributes on the RHS of the functional dependency
- Full dependency: B depends on A and not dependent on proper subset of A
- Partial dependency: B depends on A and on at least one proper subset of A
- Transitive dependency: If B depends on A and C depends on B then C depends on A. THis is BAD!
Closure of a set F of dependencies
The closure denoted F+ is the set of all functional dependencies that are implied by dependencies in F
To compute the closure F+ of F we need some interference rules
Armstrong's axioms:
- Reflexivity: If B is subset of A then A → B
- Augmentation: If A → B, then A,C → B, C
- Transitivity: If A → B and B → C, then A → C
- Decomposition: If A → B, C then A → B and A → C
- Union: If A → B and C b→ D, then A, C → B, D
Algo for computing the closure of F+
- For every func. Dependency f in set F+
- Apply rule sof reflexivity and augementation to f
- add these new func dep to set F+
- For each pair of func dep. if another function is implied by the first two using transitivity then add that func to the set F+
- Keep going till F+ does not change any more.
6: Normalisation II
Normalisation process
This is a multi-stage process, where the result of each stage is called a normal form. At each stage we do a check to see if the specific criteria is satisfied and if it isn't we have to reoranise.
Unnormalized form
repeating group: Attribute values that repeat. Attributes should only have one value for each cell.
- This can contain one or more repeating groups
- Two rows may be the same
First Normal Form
- Removes all repeating groups by either flatting the table (creates redundancy) or creating a new table to store repeated values.
- 1NF gets rid of repeats which makes it a relational database but doesn't fix dependencies.
Second Normal Form
Is in 1NF and there are no partial functional dependencies. This means every non-key attributes depends on the whole primary key. E.g you can't work out a non-key attribute without knowing the primary key.
Whole primary key: the set of Keys which allow you to uniquely identify the set of attributes
So, perhaps a subset is dependent on one primary key and another subset dependent on the whole primary key. If this is the case then there is a partial dependency.
To convert to 2NF we do:
- Remove the partial dependent attributes
- And then place it in a new relation.
Third Normal Form
This gets rid of transitive dependencies. This means getting rid of cells that are dependent on another non-candidate key.
- Remove the transitive keys by creating new tables.
7. Structured Query Language
SQL components
- Sql - Common database language that is easy to learn
- Data definition language - component of Sql that is used to change the database meta data
- Data manipulation language - component of SQL that is used to change data in database
Writing SQL statements
- reserved words - Commands in the SQl that must be spelt correctly(these should be capitalised)
- User-defined words - Words made by user
- Case insensitive - You should probably use capitals for reserved words and
Views
- essentially a subset of the main table which isn't stored, but is instead generated using a predefined query.
- Used to make queries simpler.
- Restrict access to database.
8. Relational Calculus and Algebra
Relational Calculus
- Relational calculus is query language which tells us what data we want but not how to get it.
- it uses the existential quantifier "there exists" and the universal quantifier "For all".
- We give it free variables and bound variables and expect an output which matches the requirements.
Relational Algebra
With this we describe the data by the operations applied to get it.
There are 6 basic operations:
- Selection (σ) - Select subset of relation that matches predicate.
- Projection () - returns subset of relation with specified attribute columns and removes duplicates.
- Rename - Return relation with renamed attributes.
- Union - Joins two relations which are union compatible (same number of attributes and corresponding attributes have same datatype)
- Set difference - Removes elements in one relation that are present in the other relation (must be union-compatible)
- Cartesian product - Returns relation that is a concatenation of every tuple in R with every tuple in S (no compatibility needed!)
Derived operations:
- Intersection - Returns elements that are present in both relations (must be union-compatible)
- Division - R(x,y) div S(y) means gives all distinct values of x from R that are associated with all values of y in S.
- Join - Joins columns of two tables according to a predicate
9.Relational algebra in depth
Selection (σ)
- This selects part of a relation according to the predicate.
- Returns a "horizontal slice" of the DB which matches the conditions. (e.g all rows WHERE x=1.
- It cannot add/remove columns
Projection ()
- This takes the data and returns only the specified columns of that data.
- Like a "vertical slice"
Union, Set difference, intersection
These are all the same as their set counterparts (except they require compatibility) so lets go quick through them.
Union
- Outputs the union of two relations
- The result will not contain duplicates, if the same tuples appeared in both relations.
Set difference
- Removes any common rows between R and S.
Intersection
- Returns only the tuple rows which are common between both
Compatibility of schemas
Inorder for union, set difference or intersection to work the schemas must match.
So same number of attributes and corresponding attributes must have same domain. Note: not same name, just same domain.
Cartesian product
- Returns the concatenation of each row in R with each row in S.
- Order does not matter since it returns ALL possible ones.
- if two attributes have the same name they are prefixed with their relation name.
Rename
- This renames a relation to something else.
- Can be used to create a copy of a relation when doing a join
- Can also be used to simplify queries so that we don't need to use the full relation name every time we reference it.
Join
Joins are cartesian products plus a selection.
equijoin: this is a type of join where the selection involves the equality operator.
Natural join ()
$$R \bowtie S = \Prod_{C_1, \dots, C_2} (\sigma_{R.A_1=S.A_1, \dots, R.A_k =S.A_k)(R \times S)) $$
This is an equijoin between the relations R and S, over all their attributes that have the same name, without duplicates.
Steps to do a natural join:
- (It takes the cartesian product between R and S)
- For each attribute with the same name A in both R and S, select all rows where R.A = S.A
- Removes duplicate columns using a projection.
Outer join
- Left outer join: R ⟕ S
- Right outer join: R ⋊ S
This computes the natural join of R and S, and then adds tuples which did not match between R and S.
left outer join: Adds tuples from R which did not match those in S.
Right outer join: Adds tuples from S which did not match those in R.
Full outer join: Adds tuples from either which didn't match.
Semi join
the natural join between R and S. However with only the attributes of R
10. Multi-User Architectures
Teleprocessing architecture
- The traditional architecture.
- Many terminals connected to the cental computer
- Terminal sends messages to the central computer
- All data processing done in the central computer
File-server architecture
- Processing distributed around a computer network
- Every workstation has its own DBMS and its own user application
- The workstation requests the files it needs from the file server, which acts like a shared hard disk
- This requires sending who tables to the user terminal from the file server which causes a large amount of network traffic.
- A full DBMS must be stored on each workstation and having concurrency /recovery is more difficult.
Client server architecture
- Client requires a resource and the server provides the resource.
Two tier architecture
- Client does presentation of data
- Server supplies data services to the users.
- User gives a request to the client, which generats the sql query and sends it to the server. Then the server accepts it and sends the result to the client. Then the cliet formats the result for the user.
- Has increased performance, reduced costs and reduced communication costs.
Three tier architecture
- Tier 1 - user interface
- Tier 2 - application server
- Tier 3 - database server
This is literally how the internet browser works.
Distributed DBMS
This has network of computers each with part of the database, which mirrors the organisational structure.
Aims to:
- Make all data accessible to all units
- Store the data close to the location where it's used most.
Distributed DBMS is the software system that manages the distributed database and makes the distribution transparent to the users.
- Split into fragments
- Each fragment stored on one or more computers under the control of a seperate DBMS.
- Every computer makes up a communications network
- Sites have local autonomy.
- Sites have access to global applications
- Not all sites have local applications but all site have access to global applications.
Distributed processing vs distributed DBMS
Distributed processing is a centralised database that is accessed over a computer network. But Distributed DBMS has multiple DB fragments distributed across sites.
Design of distributed DBMS
- Fragmentation - break relation into fragments
- Allocation - How to allocate the fragments optimally.
- Replication - Which fragments are stored at multiple sites (redundantly duplicated data)
How to do this depends on Quantitative information and Qualitive information
View count: 12426